
BAM - Bottleneck Attention Module
Paper link : https://arxiv.org/abs/1807.06514
Abstract
- 최근 Deep Nueral Network의 발전은 더 강한 표현력을 가진 architectur 탐색을 통해서 개발되어짐
- 본 논문에서는 일반적인 Deep Neural Networks의 Attention의 effect의 집중
- BAM(Bottleneck Attention Module), Attention 모듈을 제안
- Channel 과 Spatial 두가지 path로 Attention Map을 추론
- feed-forward convolutional Neural Network와 통합하여 End To End 방식으로 학습
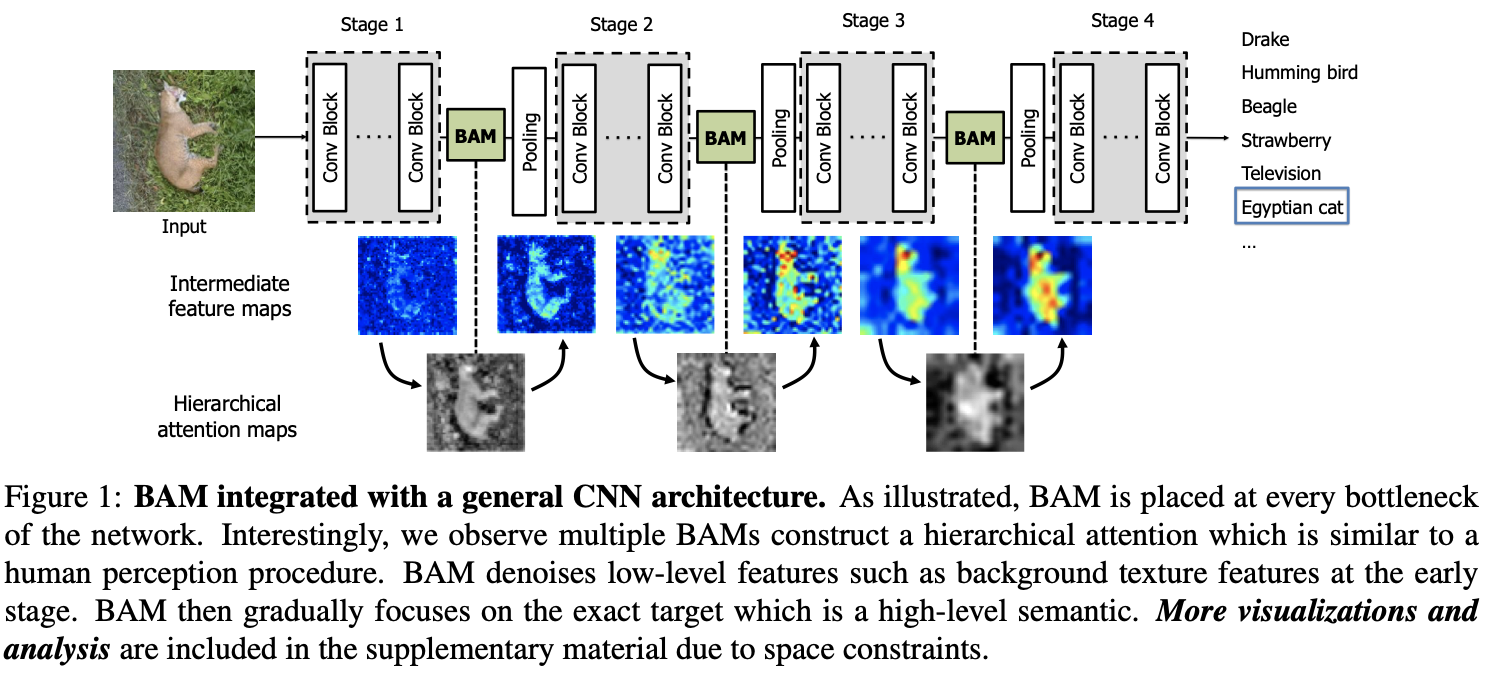
- 모듈을 각 model에서 feature map의 downsampling이 발생하는 bottlenect 지점에 배치
Introduction
-
기존 Deep learning 아키텍처에서 각 task별 성능을 향상시키기 위해 layer를 더 많이 쌓거나, 채널의 수를 늘린다던지, reception field를 높힌다던지 하는 다양한 방법으로 노력을 해왔음.
-
본 논문에서는 이전의 접근 방식과 다른 DNN에서의 Attention의 effect를 조사하고, 일반적인 DNNs or CNNs 를 위한 모듈 BAM(Bottleneck Attention Module) 을 제안
-
BAM 중요한 element를 강조하기 위한 3D Attention Map을 만드는 모듈
-
두가지(공간, 채널)로 분리하여서 ‘무엇’과 ‘어디’에 집중해야하는지 학습하게 됨
-
Contribution
-
다른 모델에 통합가능한 BAM 을 제안
-
광법위한 연구를 통해 BAM의 설계를 검증
-
여러 벤치마크(CIFAR-100, ImageNet-1L, VOC 2007, MS COCO)에서 다양한 baseline 아키텍처를 통해서 효과를 검증
-
Related Work
- Cross-modal attention
- Attention mechanism은 multi-modal에서 광범위하게 사용되는 기법
- VQA task에서 자연어 질문에 대하여 이미지에서 attention mechanism은 이미지 feature에서 질문과 관련된 영역을 선택함.
- 또 다른 방식으로 양방향 추론에선 텍스트와 이미지 모두에서 attention map을 생성
- Attention mechanism은 multi-modal에서 광범위하게 사용되는 기법
- Self-attention
- DNNs에서 feature extraction과 attention generation을 end to end 방식으로 학습
- Wang et al. - Residual Attention Networks
- 파라미터, 계산적인 오버헤드가 큼
- Hu et al. - Squeeze-and-Excitation , SENet
- 어떤 채널이 중요한지, 하지만 공간적인 축을 놓침
- Adaptive Modules
- 입력값에 따라 출력값을 바꾸는 Adaptive Module을 사용
- Dynamic Filter Network
- 입력값을 기반으로 Convolutional 특징이 생성하는 것을 제안
- Spatial Transformer Network
- 입력 특징을 사용하여서 affine 변환의 파라미터를 생성하도록 제안
- Deformable Convolutional Network
- pooling offset이 입력 특징으로 부터 생성이 되도록 제안
- pooling offset이 입력 특징으로 부터 생성이 되도록 제안
Bottleneck Attention Module
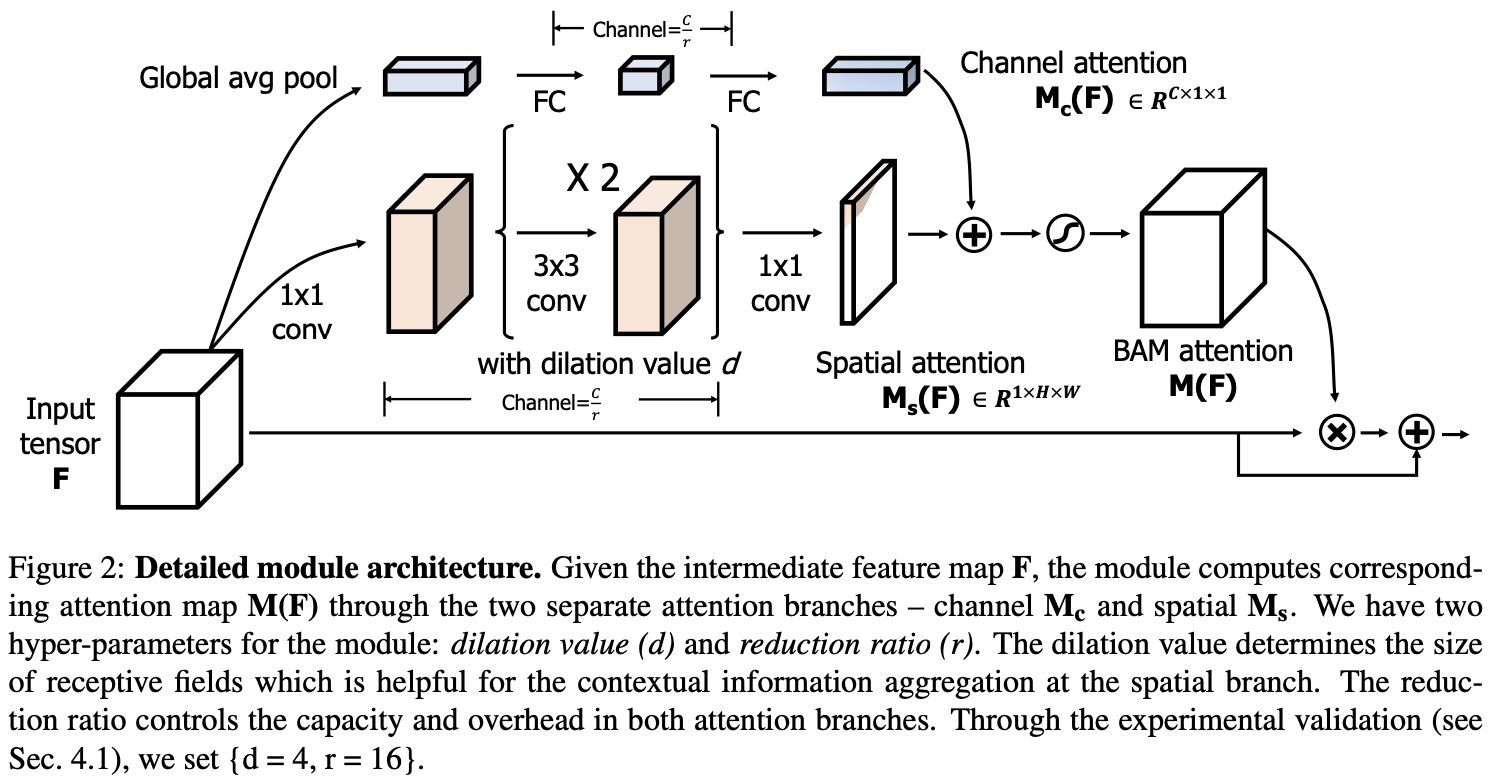
- input feature map \(F \in \mathbb{R}^{(C\times H \times W)}\) 이 주어졌을 때, BAM은 \(M(F) \in \mathbb{R}^{C\times H \times W}\)의 3D attention map을 추론하고 refine된 feature map은 아래와 같이 계산할 수 있음
-
3D attention map 을 2가지 브랜치로 나누어서 계산
- Channel attention : \(M_c(F) \in \mathbb{R}^C\)
- Spatial attention : \(M_s(F) \in \mathbb{R}^{H \times W}\)
- \(M(F)\) as
- sigmoid는 2개 브랜치의 결과를 resized 하기 위해 사용
-
Channel attention branch
-
global average pooling을 통해서 각 채널의 context를 포함한 벡터를 생성함.
-
parameter overhead를 줄이기 위해서 \(\mathbb{R}^{C/r\times 1 \times 1}\)의 hidden activation size를 사용한 MLP를 사용하여 채널 벡터로 부터 attention을 추정함.
-
- Spatial attention branch
- 다른 공간 위치에 따라서 feature를 강화하거나 억제하기 위한 spatial attention map \(M_s(F)\)를 생성
- 어떠한 공간적 위치에 focus 해야하는 알기 위해 contextual information 정보를 활용하는 것이 중요
- contextual information을 효과적으로 사용하기 위해서 큰 receptive field가 필요하므로 dilated convolution을 사용함.
- 1x1 conv, two 3x3 dilated conv, 1x1 conv 사용
- Combine two attention branches
- channel attention과 spatial attention을 각 브랜치로 부터 만든 후, element-wise summation을 사용해서 3D attention map \(M(F)\)을 생성
- 그후 0 ~ 1 사이 값을 취하기 위해서 sigmoid를 사용 feature map \(F\)에 곱하고 더하여 \(F'\)를 만든다.
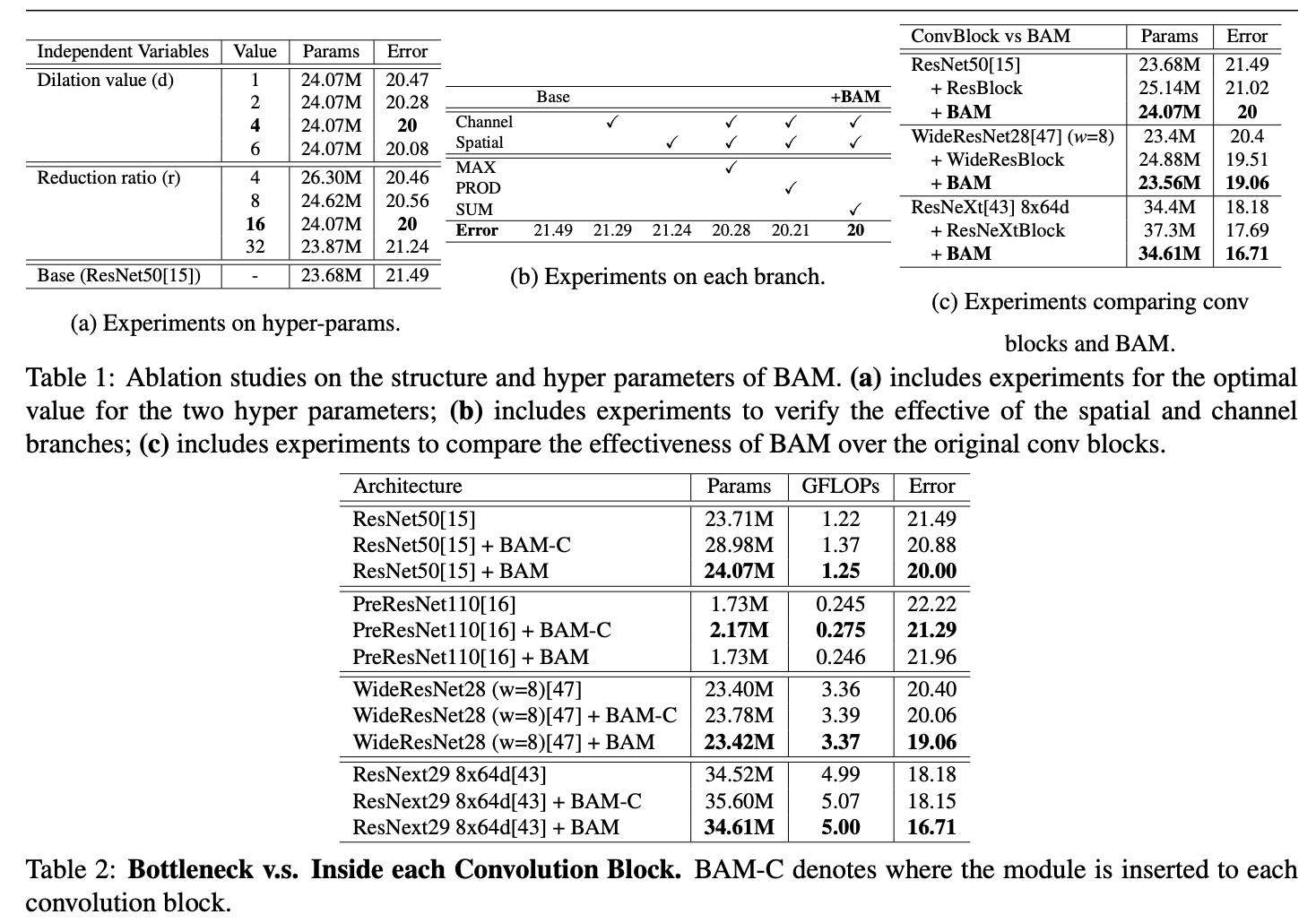
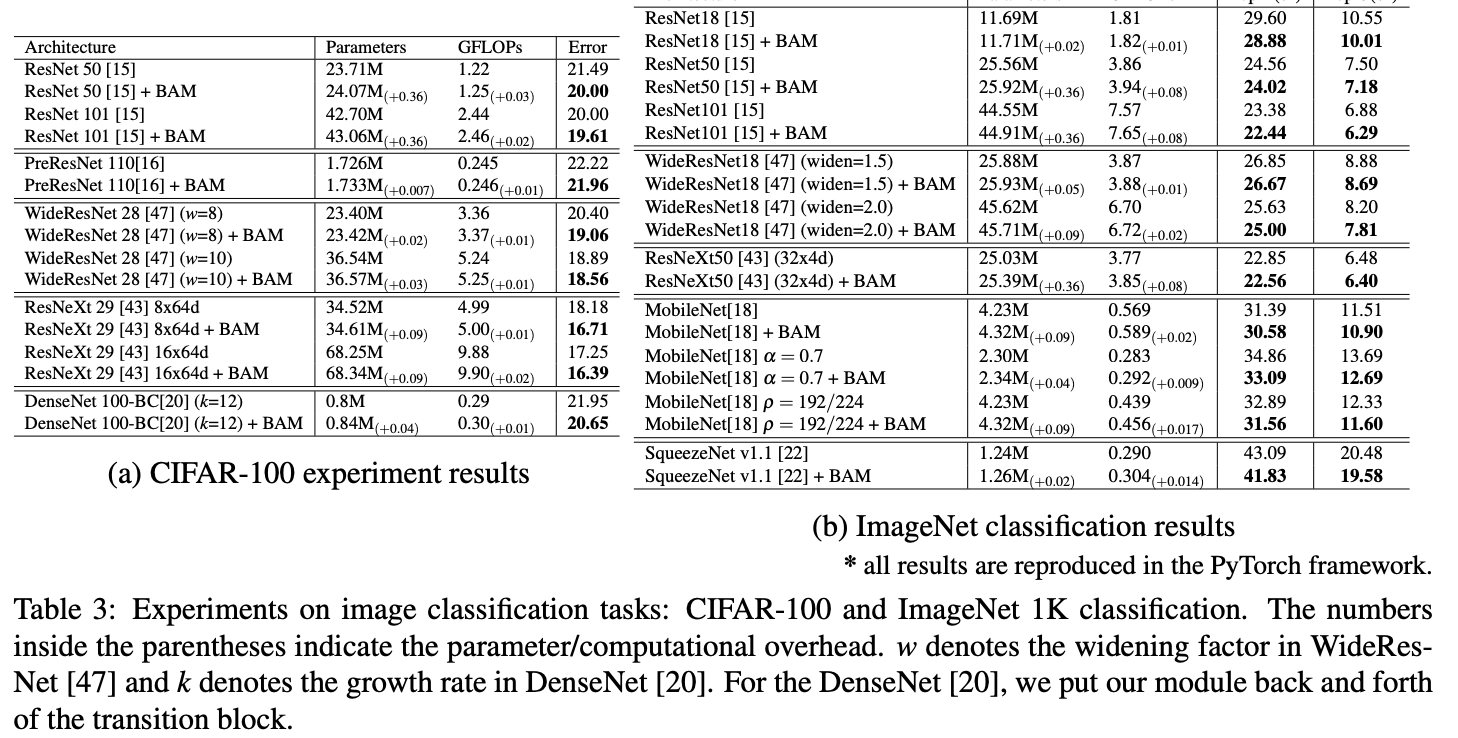
Experiments
댓글남기기