
Boosting 기법 정리
캐글에서 머신러닝 성능을 끌어올리기 위해서 Bagging, Boosting, Stacking 등 기법을 많이 사용하고 있는데, 그 중 하나인 Boosting 기법에 대한 설명과 몇가지 Boosting 방법을 정리한 글
Boosting
Boosting은 약분류기(Weak Classifier)를 이용해서 강분류기(Strong Classifier)를 만드는 방법으로 약분류기를 직렬로 연결해서 앞선 Classifier에서 제대로 분류하지 못한 부분에 대하여 boosting을 하는 알고리즘이다.
Boosting의 경우 순차적으로 모델을 학습 시켜서 오답에 대하여 집중하여 후순위 모델을 학습하기 때문에 보통의 경우, 정확도가 더 높게 나타나게 되며, 그 만큼 Outlier에 약할 수 있고, 오버피팅이 될 가능성이 높다.
출처 : https://medium.com/swlh/boosting-and-bagging-explained-with-examples-5353a36eb78d
AdaBoost
Adaptive Boosting의 약자, 가중치를 부여한 약 분류기를 모아서 분류기를 만드는 기법이다.
Boosting에서 가장 기본적인? 방법이며, 앞선 분류기에서 제대로 분류하지 못한 케이스에 대하여 가중치를 adaptive하게 바꾸어 학습하면서 전체적인 성능을 올리는 기법
학습 데이터에 outlier가 있다면 후순위에 약분류기를 학습하는 과정에서 취약한 점이 있으므로, 데이터에 따라 어떤 부스팅 알고리즘을 사용할지 선택을 잘해야한다.
AdaBoost의 개요
AdaBoost의 약분류기는 feature 하나를 가지고 if문 하나정도의 depth를 가진 분류기라고 가정을 한다면, 처음 학습이 되는 분류기는 feature의 값이 특정 threshold 이상인지 체크하는 정도의 분류기가 만들어 질 것이다.
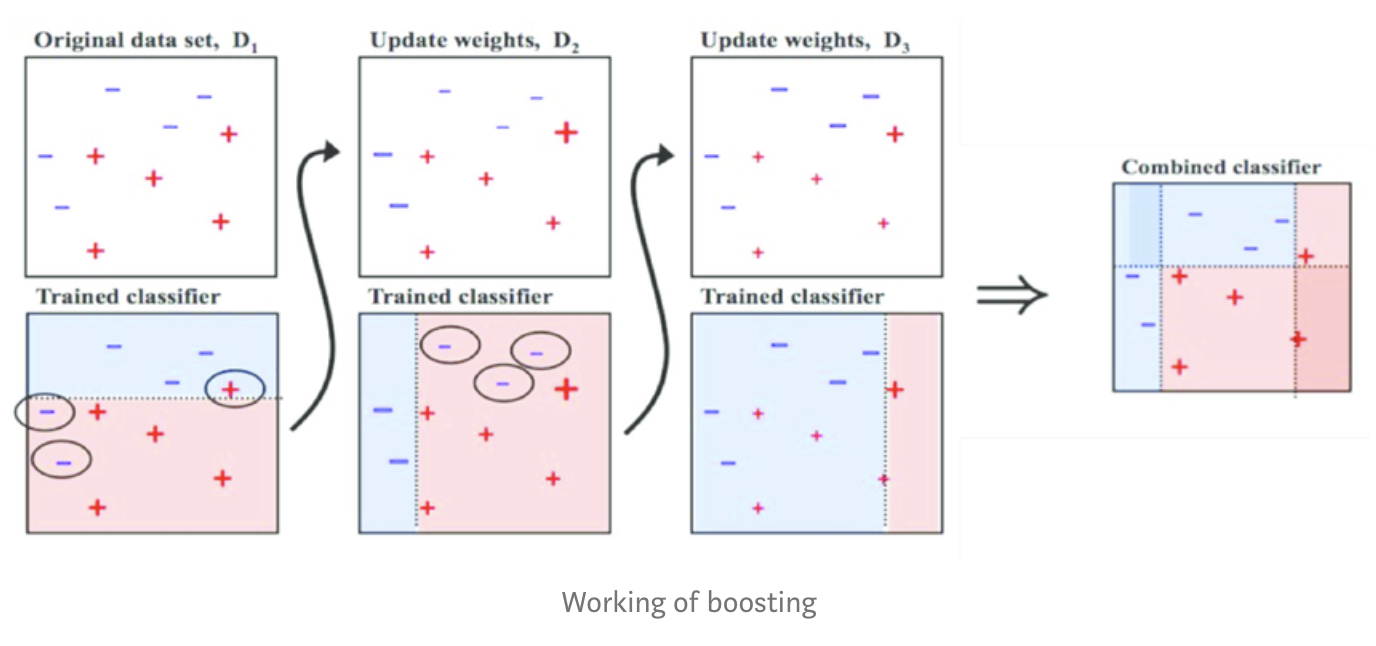
위 그림이 AdaBoost을 나타내는 심플한 그림이다.
첫번째, 1번 모델에서 학습한 뒤 분류한다, 분류가 되지 못한 데이터에 대하여 가중치를 부여한다.
두번째, 가중치를 반영하여서 잘못 예측된 데이터를 더 잘 분류할 수 있도록 2번 모델을 학습한다.
세번째, 3번 모델은 1,2번 모델이 잘 못 예측한 데이터를 분류하도록 학습을 한다.
네번째, 각 모델별로 가중치를 계산한 후, 모델을 합쳐 최종 모델을 생성한다.
AdaBoost 알고리즘
Input: training set \(X_{train} = \{x_t, y_t\}, i = 1, ... , N;\) \(\ y_i \in \{-1, 1 \};\) \(T;\ number\ of\ iterations;\)
\(D_t(i)\) : weight of example \(i\) in \(X_{train}\) at iteration \(t\)
Output: final classifier, \(H(x) = sign(\sum_{t = 1}^{T} a_th_t(x))\), where \(h_t\) is the induced classifiers (with \(h_t(x) \in \{-1,1\})\) and \(a_t\) is assifned weights for each classifier
Step 1 : \(D_1(i) \leftarrow {1 \over N}\) for \(i = 1, ..., N\)
Step 2 :
for \(t = 1\) to \(T\) do
\(h_t \leftarrow\) base_learner( \(X_{train}, D_t\) )
\(\epsilon_t \leftarrow \sum_{i = 1}^{N} D_t(i)[h_t(x_i) \ne y_i]\)
\(\alpha_t = {1 \over 2 } ln({1 - \epsilon_t \over \epsilon_t})\)
\(D_{t+1}(i) = D_t(i) \times e^{(-\alpha_th_t(x_i)y_i)}\) for \(i = 1, ..., N\)
Renormalize \(D_{t+1}\)
end for
final : \(H(x) = sign(\sum_{t = 1}^{T} a_th_t(x))\)
step 1에서 초기에서는 모든 데이터가 같은 가중치 값으로 가지지만, 데이터가 잘 분류 되었으면 step 2에서는 해당 D에 가중치는 점점 낮아지게 된다.
이런식으로 계속 데이터에 대한 가중치를 변경해가면서, classifier를 만들어 간다.
GradientBoost
AdaBoost는 weight가 낮은 데이터 주위에 높은 weight를 가진 데이터가 있으면 의도치 않게 잘 못 분류가 되면서 성능이 크게 떨어지는 단점이 있다.
이를 GB는 Gradient Descent 알고리즘을 사용하여서 오류값을 최소화 하는 방식으로 학습을 하게 된다.
예로 Mean Squared Error를 쓰는 경우라면, 현재 모델의 MSE의 미분값인 residual을 target으로 두고 다음 모델을 학습함으로써 이전 모델에서 오류를 다음 모델에서 줄일 수 있도록 한다.
GradientBoost의 개요
\(Loss = MSE = L(y_i, f(x_i)) = L(y_i, \overline{y_i}) = \sum (y_i - \overline{y_i})^2\)
\(where, y_i = target\ value,\ \overline{y_i} = predction\)
여기서 loss function을 MSE로 정의하고, 아래와 같이 loss function을 미분해 보면 negative gradient는 residual이 된다.
\({\partial L(y_i, f(x_i)) \over \partial(x_i)} = {\partial [{1 \over 2}(y_i - f(x_i))^2] \over \partial f(x_i)} = f(x_i) - y\)
위와 같은 종류를 gradientBoost 중에서 residual을 사용하기 때문에 residual fitting model이라고 부르며, 다른 loss function을 사용해도 negative gradient을 유도하고 새로운 model의 target으로 fitting하는 방식으로 최종 모델을 만들어간다면, GradientBoost가 된다.
GradientBoost 알고리즘
Input: training set \({\displaystyle \{(x_{i},y_{i})\}_{i=1}^{n},}\) a differentiable loss function \(L(y,F(x))\), number of iterations M.
Algorithm:
- Initialize model with a constant value: \(F_0(x) = argmin_\gamma \sum^n_{i=1}L(y_i, \gamma)\) : baseline model
- For m = 1 to M:
- Compute so-called pseudo-residuals(negative gradient): \(\tau_{im} = - [{\partial L(y_i, F(x_i)) \over \partial F(x_i)}]_{F(x)=F_{m-1}(x)}\ for\ i = 1, ..., n.\)
- Fit a base learner (or weak learner, e.g. tree) \(h_{m}(x)\) to pseudo-residuals, i.e. train it using the training set \(\{(x_{i},r_{im})\}_{i=1}^{n}\).
- Compute multiplier \(\gamma_{m}\) by solving the following one-dimensional optimization problem: \(\gamma_m = argmin_\gamma \sum_{i=1}^nL(y_i,\ F_{m-1}(X_i) + \gamma h_m(x_i))\)
- Update the model: \(F_m(x) = F_{m-1}(x) + \gamma_mh_m(x)\)
- Output \(F_{M}(x).\)
XGBoost
기존 GB나 AdaBoost 방법은 성능은 좋지만, 학습/연산 시간에서 매우 느리다. XGBoost는 GB에서 이러한 시간적인 요소를 개선한 오픈 소스 구현체.
how? 분산/병렬 환경에서 DT 생성시 병렬로 처리를 하여서 기존 GB 보다 성능을 업, 기타 추가적인 최적화들도 들어 있는 듯함.
XGBoost docs : https://xgboost.readthedocs.io/en/latest/tutorials/model.html
비슷한 라이브러리 : lightGBM
XGBoost, lightGBM 등 GB에 대한 구현체를 사용할 때는, 파라미터 조절이 굉장히 중요하다고함.
-
tree based model은 전반적으로 오버피팅을 할 가능성이 높으므로, 적당히 pruning을 하거나, 정규화를 잘 걸어줘야함
-
XGBoost에서는 결측치도 내부적으로 처리를 해준다고 하긴함.
댓글남기기